
Fun with IBM RXN
25 July 2021 - Transformers
 I have discussed organic reaction data mining in this blog last year. (link) In this type of exercise an organic synthesis laboratory procedure written down in some supplemental info source is analyzed by a computer algorithm with all relevant information (reactants, reagents with amounts and units, different action such as mixing, stirring and heating) extracted for storage in a database. The information then allows you to for instance put a synthesis robot to work and perform the actual synthesis described in the procedure. One pioneer is Leroy Cronin of Glasgow University and his Chemify has the look and feel of a startup but the website that was made available to test out the mining algorithm is no longer available.
I have discussed organic reaction data mining in this blog last year. (link) In this type of exercise an organic synthesis laboratory procedure written down in some supplemental info source is analyzed by a computer algorithm with all relevant information (reactants, reagents with amounts and units, different action such as mixing, stirring and heating) extracted for storage in a database. The information then allows you to for instance put a synthesis robot to work and perform the actual synthesis described in the procedure. One pioneer is Leroy Cronin of Glasgow University and his Chemify has the look and feel of a startup but the website that was made available to test out the mining algorithm is no longer available.
At the occasion I did mention the data mining work done by Philippe Schwaller at IBM Research but today I found out I had completely missed the IBM RXN website he is associated with. We will take a look!
In the IBM work the machine translation from text to a list of procedure steps is based on a so-called transformer-based encoder-decoder architecture. This transformer model takes an input sentence and identifies all the relationships between the words in the sentence. For example, In the sentence "the mixture was stirred and water was added to it" the words "stirred" and "it" are both strongly related to the word "mixture". This encoder information is then transferred in a big data matrix to the decoder part which assembles the translation. Because the relationships are weighted, the architecture is said to be attention-aware. This concept was introduced by Google researchers in a landmark paper called "Attention is all you need" in 2017 (DOI) and if today you Google-translate a website, this is the technology it is based on.
The IBM RXN site allows anyone (login is required but access is free) to try out the IBM data mining solution and it works super easy. Take a procedure, for example one from the USPTO collection (file), copy & paste into the form, run and collect the result.
ADD Chlorobenzotrifluoride (18.5 g, 100 mmol)
ADD piperazine (12.9 g, 150 mmol)
ADD toluene (120 ml)
ADD tetrahydrofuran (80 ml)
DEGAS with unknown for 15 min
ADD DRYSOLUTION over sodium tert-butoxide
DEGAS with unknown for 10 min
ADD 2-(2,6-dimethoxyphenyl)phenyldicyclohexylphosphine (41 mg, 0.1 mmol)
ADD (dibenzylideneacetone)palladium (20 mg, 0.025 mmol)
ADD THF (10 ml)
STIR for 30 min under nitrogen
SETTEMPERATURE room temperature
STIR for 8 h at 90° C
SETTEMPERATURE 50° C
FILTER
EXTRACT with dilute hydrochloric acid
COLLECTLAYER aqueous
PH with sodium hydroxide solution to pH 10
FILTER keep precipitate
DRYSOLID under vacuum
YIELD N-(4-trifluoromethylphenyl)piperazine (21.4 g, 93 mmol, 93%)
And not only there is the website but the source code is also available and an API. (at github). This opens up a new avenue for the KMT automated organic reaction harvesting project: supplemental info (with proper data) >> IBM RXN >> Opsin >> MariaDB >> RDKit.
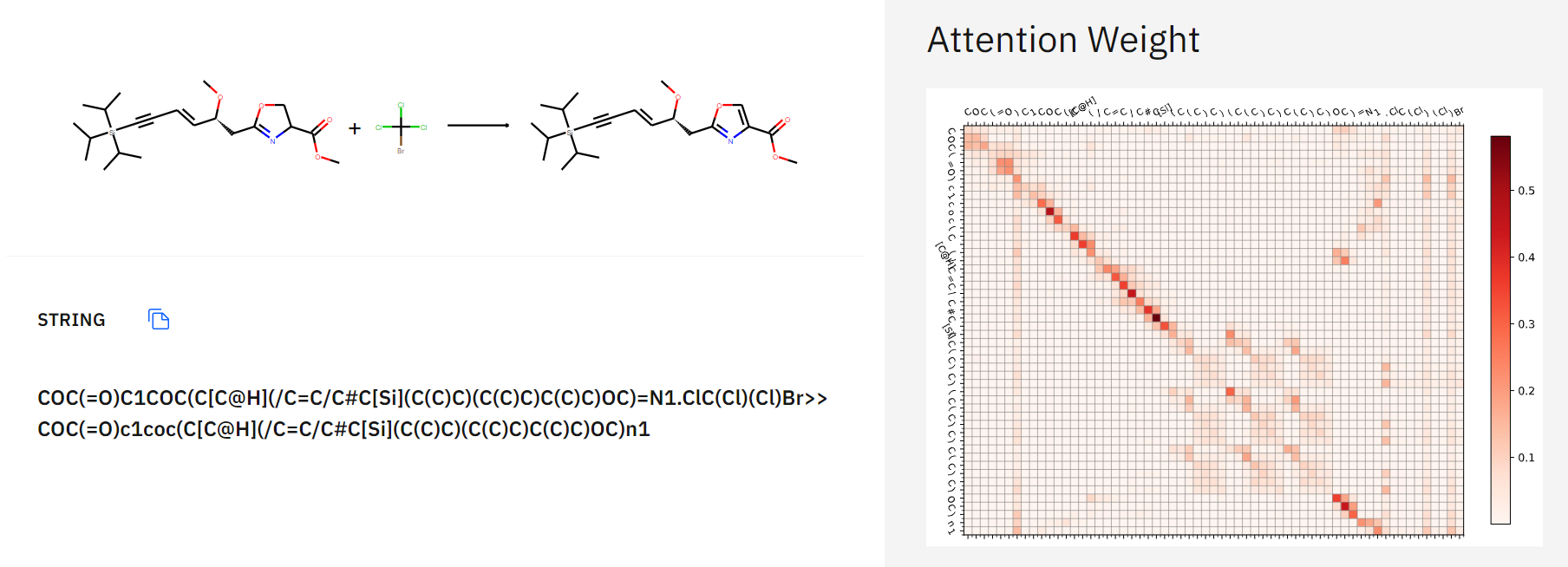
The site has another feature: reaction prediction! Take any two reactions and an algorithm will give you the product. This section is based on work published in 2019 (DOI) and surprisingly this algorithm also works via a transformer model but instead of translating English sentences, the input is now a SMILES reaction string.
In one result (with this reaction) depicted below, the input is the first part of the SMILES string. In the diagram on the right, the relationships between the different atoms are made visible. The prediction is pretty good given that it is a pretty obscure oxidation reaction, the base was left out and the reaction was also published just three months ago.